Obscurcissement de bytecode LLVM
Esod mumixam !
Serge Guelton,
Adrien Guinet et
Ninon Eyrolles
/me
Serge « sans paille » Guelton
$ whoami
sguelton- Ingénieur R&D à QuarksLab pour les parties compilations
- Chercheur associé à Télécom Bretagne
Embauché par QuarksLab pour développer un « obfuscateur de code sur étagère »
Obscurcissement de code
Objectif
Rendre une application livrée à l'utilisateur difficile à analyser
~= Faire en sorte qu'une analyse en « boîte blanche » de l'application n'apporte rien par rapport à une analyse en boîte noire
Applications
- Protection de propriétés industrielles
- Protection de clefs cryptographiques
- Mécanisme de licences à protéger
- Systèmes anti-copie [DRM :-)]
Niveau(x) d'application

Obfuscation du code source (e.g. Javascript)
Obfuscation de la représentation intermédiaire (e.g. Bytecode Python)
Obfuscation du binaire (e.g. Packer de jeu)
Pourquoi se placer au niveau LLVM ?
- Évite de dupliquer l'effort pour des langages différents
- Et pour des cibles différentes
- Infrastructure modulaire et mûre (industrie...)
- Compatible avec de nombreux projets en cours (Android Art, McSema...)
$ clang a.c -Xclang -Xload LLVMMyObf.so -my-obf -mllvm -my-obf-ratio=15Catégories d'Obfuscations visées
- Obfuscation du flot de contrôle
- Obfuscation des données
- Techniques anti-reverse (e.g. anti-debug, packer)
Quelles obfuscations choisir ?
- Duplicate basic block
- Variable splitting / merging
- Function cloning / inlining / outlining
- Opaque predicate
- Control Flow Graph Flattening
- On-the-fly data encryption / decryption
- Integrity Control
- Virtual Machine generation
- ...
Critères utiles
- Protection contre une analyse statique ?
- Protection contre une analyse dynamique ?
- Réversibilité de la transformation ?
- Introduit une complexité technique ou théorique ?
- Surcout à la compilation ?
- Surcout à l'exécution (temps, mémoire) ?
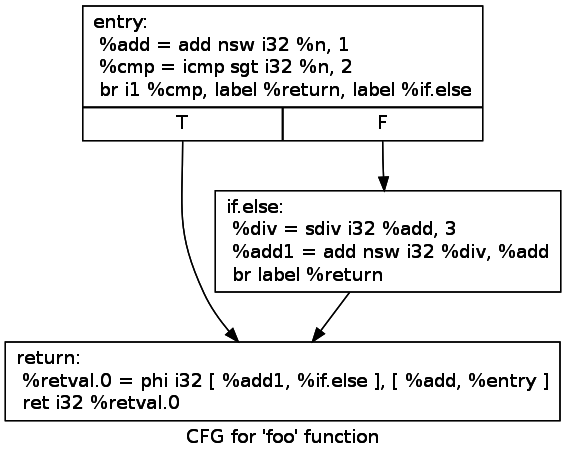
Exemple : CFG Flattening
Idée : rendre la table de transition d'état explicite
- Initialisation d'un contexte
- Calcul de l'état suivant
- Saut au basic bloc concerné
- Exécution du code correspondant
- Mise à jour du contexte
goto2.
Avant CFG Flattening
Après CFG Flattening
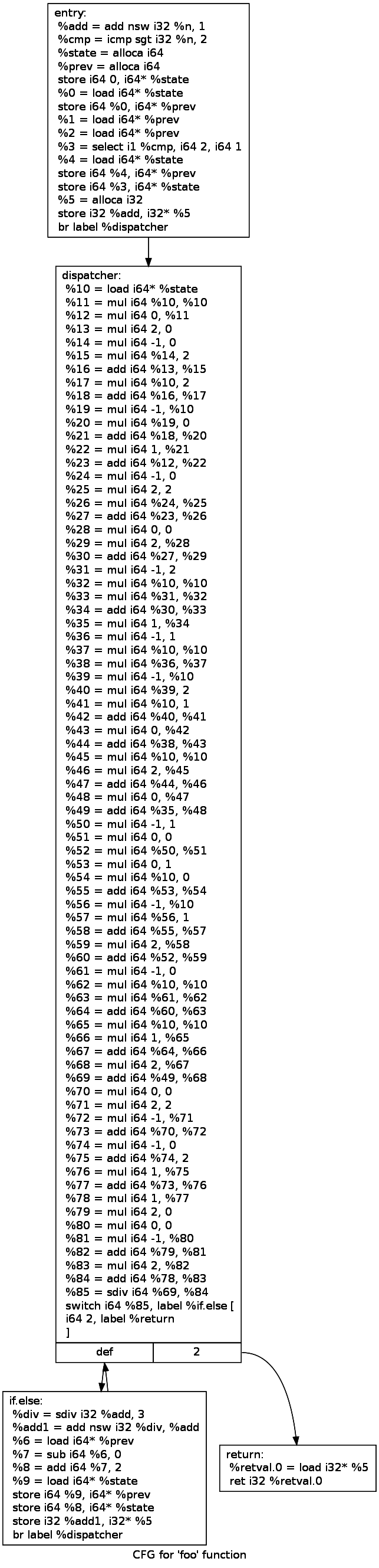
Propriété du CFG Flattening
- Protection contre l'analyse statique
- Peut ralentir significativement l'exécution
- Peut augmenter significativement la taille du binaire généré
- Introduit une difficulté technique, mais pas théorique
- Nécessite une fonction de dispatch obfusquée pour résister aux optimisations de LLVM
Exemple : Random Outlining
Idée : transformer le graphe d'appel en graphe aléatoire
- Inliner le maximum de fonctions
- Sélectionner un sous ensemble aléatoire du CFG
- L'outliner dans une nouvelle fonction
goto2.
Après Random Outlining
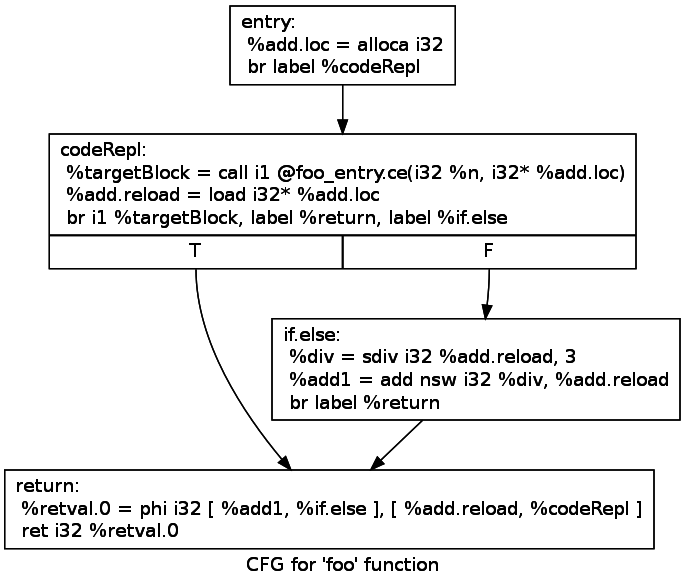
Propriété du Random Outlining
- Introduit une perte d'information irréversible
- Peut ralentir significativement l'exécution
- Augmente légèrement la taille du binaire généré
Exemple : SSExy
Idée : vectoriser toutes les opérations arithmétiques scalaires (en ajoutant des opérandes inutiles si besoin)
- Calculer le graphe de dépendance d'un basic bloc
- Regrouper les instructions ordonnancables par instructions similaires
- Compléter les groupes avec des opérandes inutiles issues du contexte
- Ordonnancer ces instructions, puis
goto2.
Une fonction d'extraction (obfusquée) est utilisée pour extraire les opérandes d'instructions non vectorisables
Credits : jbremer
Propriété de SSExy
- Introduit une difficulté technique (support d'AVX/SSE par les outils de reverse)
- Protection contre l'analyse statique et dynamique
- Peut ralentir l'exécution (ou l'accélérer !)
- Influe peu sur la taille du binaire généré
Après SSExy

Contrôle de la granularité
Problème : trop de protections rendent le programme inutilisable (compromis temps d'exécution / taille du binaire / niveau d'obfuscation)
- Contrôler le ratio d'application d'une passe (e.g. 20% des basics blocs)
- Filtrer les fonctions obfusquées (e.g. uniquement une fonction de chargement de clef)
- Uniquement des portions de code délimitées par des directives
Sujet intéressant de compilation itérative avec optimisation multi-critères !
Limitations liées à LLVM
Optimisation d'une métrique inhabituelle !
- RI parfois peu adaptée à l'obfuscation
- Incompatible avec certains intrinsèques (e.g.
llvm.lifetime.*) - Difficile de maintenir la cohérence des infos de debug
- Instructions
phiincompatibles avec certaines passes (cfg flattening...) - Problèmes de complexité : obfusquer toutes les constantes de tous les basic blocks d'une fonction génère des blocs de taille dégénérée
Pensées finales
Sécurité par l'obscurité...
- Ralenti / décourage mais n'empêche pas
- Supprimer les éléments structurants
- Situations correspondant à des problèmes difficiles (aliasing...)
- Peu d'obfuscations spécifiques contre l'analyse dynamique
Accessoirement très ludique à implémenter ;-)
From the HITB challenge
(lambda g, c, d: (lambda _: (_.__setitem__('$', ''.join([(_['chr'] if ('chr'
in _) else chr)((_['_'] if ('_' in _) else _)) for _['_'] in (_['s'] if ('s'
in _) else s)[::(-1)]])), _)[-1])( (lambda _: (lambda f, _: f(f, _))((lambda
__,_: ((lambda _: __(__, _))((lambda _: (_.__setitem__('i', ((_['i'] if ('i'
in _) else i) + 1)),_)[(-1)])((lambda _: (_.__setitem__('s',((_['s'] if ('s'
in _) else s) + [((_['l'] if ('l' in _) else l)[(_['i'] if ('i' in _) else i
)] ^ (_['c'] if ('c' in _) else c))])), _)[-1])(_))) if (((_['g'] if ('g' in
_) else g) % 4) and ((_['i'] if ('i' in _) else i)< (_['len'] if ('len' in _
) else len)((_['l'] if ('l' in _) else l)))) else _)), _) ) ( (lambda _: (_.
__setitem__('!', []), _.__setitem__('s', _['!']), _)[(-1)] ) ((lambda _: (_.
__setitem__('!', ((_['d'] if ('d' in _) else d) ^ (_['d'] if ('d' in _) else
d))), _.__setitem__('i', _['!']), _)[(-1)])((lambda _: (_.__setitem__('!', [
(_['j'] if ('j' in _) else j) for _[ 'i'] in (_['zip'] if ('zip' in _) else
zip)((_['l0'] if ('l0' in _) else l0), (_['l1'] if ('l1' in _) else l1)) for
_['j'] in (_['i'] if ('i' in _) else i)]), _.__setitem__('l', _['!']), _)[-1
])((lambda _: (_.__setitem__('!', [1373, 1281, 1288, 1373, 1290, 1294, 1375,
1371,1289, 1281, 1280, 1293, 1289, 1280, 1373, 1294, 1289, 1280, 1372, 1288,
1375,1375, 1289, 1373, 1290, 1281, 1294, 1302, 1372, 1355, 1366, 1372, 1302,
1360, 1368, 1354, 1364, 1370, 1371, 1365, 1362, 1368, 1352, 1374, 1365, 1302
]), _.__setitem__('l1',_['!']), _)[-1])((lambda _: (_.__setitem__('!',[1375,
1368, 1294, 1293, 1373, 1295, 1290, 1373, 1290, 1293, 1280, 1368, 1368,1294,
1293, 1368, 1372, 1292, 1290, 1291, 1371, 1375, 1280, 1372, 1281, 1293,1373,
1371, 1354, 1370, 1356, 1354, 1355, 1370, 1357, 1357, 1302, 1366, 1303,1368,
1354, 1355, 1356, 1303, 1366, 1371]), _.__setitem__('l0', _['!']), _)[(-1)])
({ 'g': g, 'c': c, 'd': d, '$': None})))))))['$'])Interested? Give a try on http://blog.quarkslab.com